FAQ
Common questions, with short answers. Longer treatments live in Architecture, the Roadmap, and the Developer Guide.
How is this different from Headlamp / Lens?
Headlamp and Lens are general-purpose Kubernetes UIs — they
render every resource type, support every action you'd otherwise do
with kubectl, and target the day-to-day "browse and edit" loop.
KubeAtlas is only the dependency graph. It doesn't render Pods
as a list to manage them; it tells you what depends on what. The two
tools coexist — install Headlamp for "show me the cluster" and
KubeAtlas for "show me the wiring". A Headlamp plugin shipped in
v1.1 (lithastra/kubeatlas-headlamp-plugin) that embeds the
cartography topology view, per-resource Dependencies tabs, and
blast-radius mode directly inside Headlamp's cluster console:
| Sidebar entry | Cluster view | Per-resource detail |
|---|---|---|
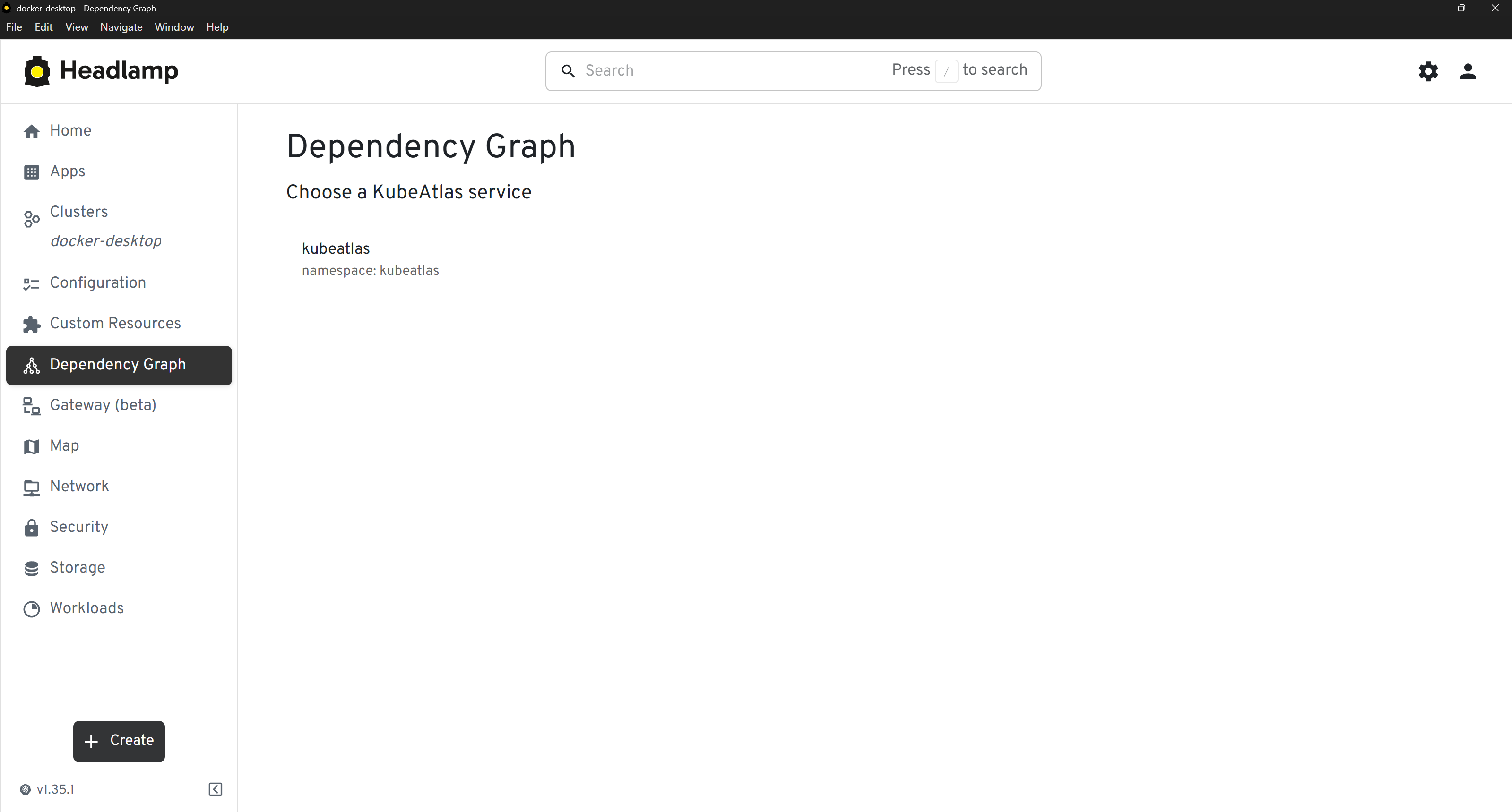 | 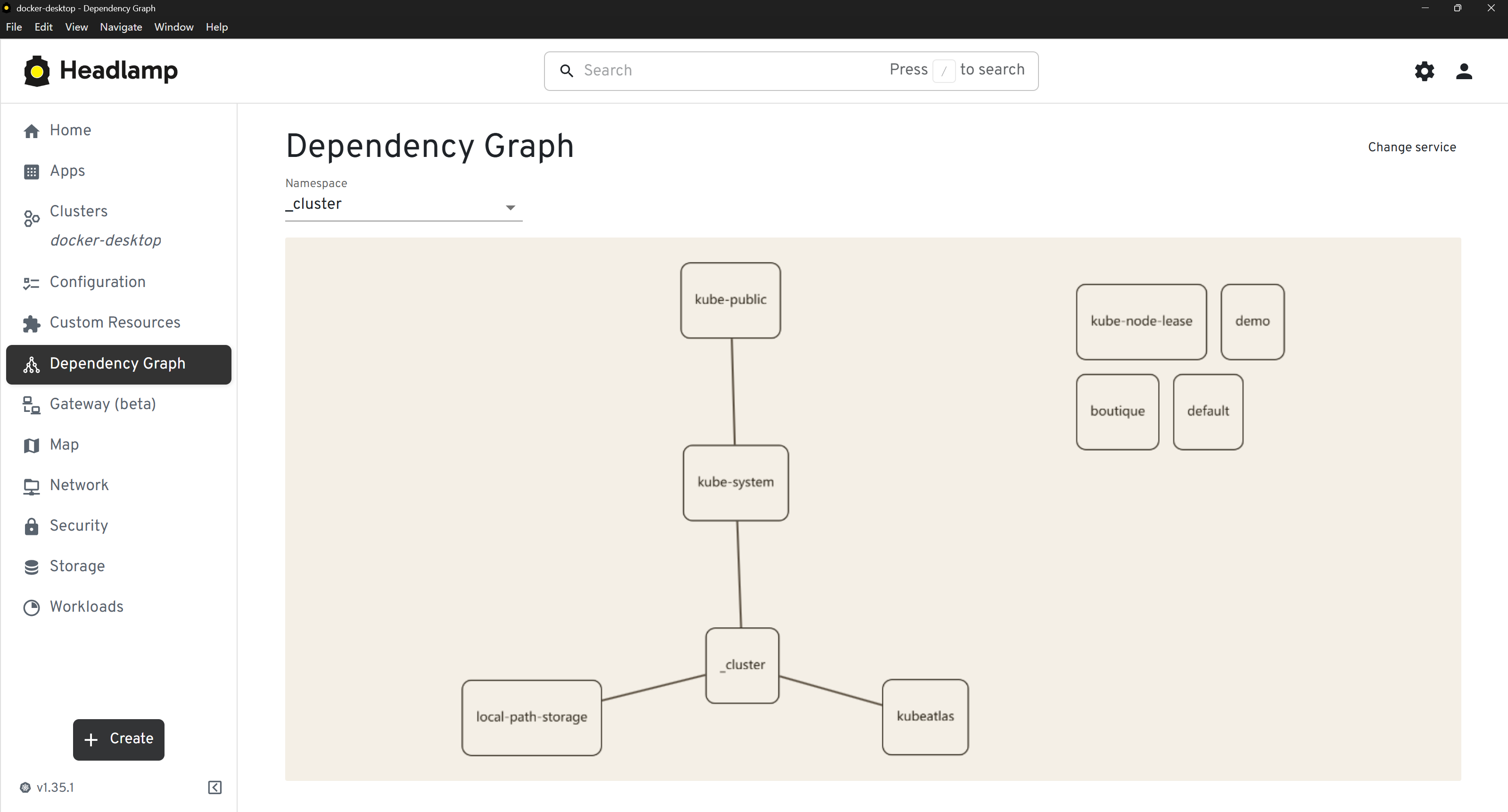 | 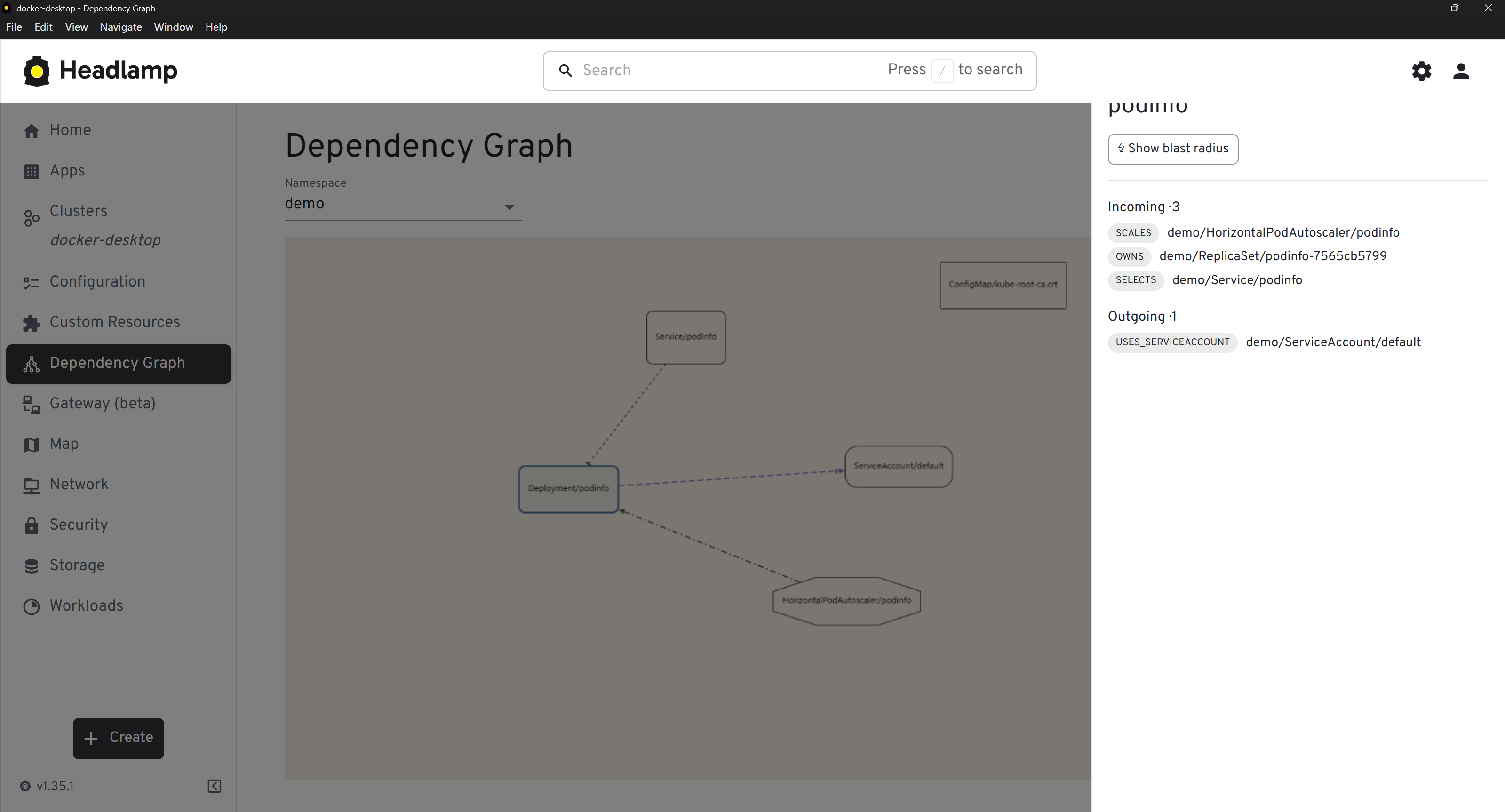 |
Can I run this in production today?
Yes — for read-only introspection. From v1.0 the chart ships an
opt-in Tier 2 backend (PostgreSQL + Apache AGE via the embedded
CloudNativePG sub-chart) so restart preserves the graph. Single-
replica is still the deploy shape. Multi-cluster federation ships
in v1.3.0 (the final Phase 3 release): one KubeAtlas instance can
attach to N kubeconfigs, the /api/v1/federation/* endpoints
return a flat federated read surface, and the Web UI's left
cluster strip picks members from /federation/clusters. See the
roadmap. Authentication is still your job — read
the security warning before
exposing the UI.
Does it work on OpenShift / EKS / AKS / GKE?
Yes — anything that exposes a standard Kubernetes API at version 1.26 or later. Discovery is GVR-driven, so platform-specific add-ons that publish CRDs work as long as the cluster has them installed.
OpenShift gets first-class support from v1.0: the detector at
startup notices route.openshift.io, auto-loads the embedded
rule pack (Route, DeploymentConfig, BuildConfig, ImageStream,
SecurityContextConstraints), and the docs include a CRC and OCP
4.x install guide — see
OpenShift installation.
Deeper platform integration (IRSA on EKS, Workload Identity on GKE, AAD on AKS) is on the v2.0+ roadmap.
How much memory does it use?
Steady state on a 1000-resource cluster is around 110 MB RSS.
The chart's default limit is 512 Mi, which leaves headroom up to
roughly 4000–5000 resources. Past that, raise
resources.limits.memory — see the
Helm reference.
What if my cluster has 50K resources?
v1.0 is comfortable in the small-to-medium range (≤ ~5K-10K
resources). Above that you'll hit two ceilings: graph footprint
in memory and JSON serialisation latency on the level=cluster
endpoint. Tier 2 storage moves the graph out of the process so
the memory side is no longer the bottleneck, but the aggregator
response shape is still O(R) — see the
stress-test-5k
fixture for a worked baseline. Response-shape pagination is a
post-v1.2 target.
Why is there no built-in authentication?
Building a good auth story for a generic web UI is a year of work on its own — OIDC IdP integrations, token refresh, session storage, RBAC mapping. The Kubernetes ecosystem already has battle-tested choices (oauth2-proxy, Pomerium, Cloudflare Access). KubeAtlas deliberately punts to those rather than ship a half-baked first version. Read the security warning before exposing the UI.
When will Tier 2 / Rego / Headlamp plugin be ready?
All shipped: Tier 2 and Rego rule packs in v1.0, the Headlamp plugin in v1.1. See the roadmap for what's next.
How do I extend it with custom edge types?
Two paths, depending on whether you want to ship a binary fork or load a rule at runtime:
- Runtime Rego rule pack — the
Phase 2 extension surface. Declare CRD edges in Rego, sign and
publish to an OCI registry, point
rulePacks.extrasat the artifact. No rebuild required. Seelithastra/kubeatlas-rulesfor the canonical examples (openshift, cert-manager). - Built-in Go extractor — for edges that should ship as
defaults. The Developer Guide has the
worked example: implement
extractor.Extractor, register inextractor.Default(), add a contract test.
Does it phone home / collect telemetry?
No. Zero outbound network calls at runtime. The binary talks to your Kubernetes apiserver and that's it — no analytics, no usage reporting, no remote config.
What's the relationship with Lithastra / PlanWeave?
Lithastra is the umbrella the project ships under. PlanWeave is a separate Lithastra product — KubeAtlas neither depends on it nor pushes data to it. The two share an organisation, not a runtime.
KubeAtlas is Apache-2.0 licensed, governed under the GOVERNANCE.md in the repo, and accepts contributions from anyone — see the Developer Guide.
My question isn't here.
Open an issue or start a discussion. FAQ entries are added when the same question shows up twice.